
通过传统的离线数据分析,企业仅能针对历史数据进行事后分析。 而随着数据量的爆发式增 长,以及市场环境和业务需求的快速变化,企业对数据时效性的 要求在不断提高。 如在互联网行业中,客户端需要满足用 户对个性化产 品和服务的需求; 在金融行业中, 企业需要更快速地进行风险控制和趋势分析; 在新零售行业中,企业需要更快速地获取 销售数据,做出业务 决策等。 因此 ,企业需要实时数据计算的能力来满足实时数据分析的需求。
在实时任务的开发过程中,任务调试是整个开发流程中比较耗时同时操作比较繁琐的环节。在调试阶段,用户普遍会面临以下几个痛点。
在调试过程中,需要验证任务代码逻辑是否正确,任务配置参数是否合理,就需要重复任务上线、运行、下线调整重启这一过程。
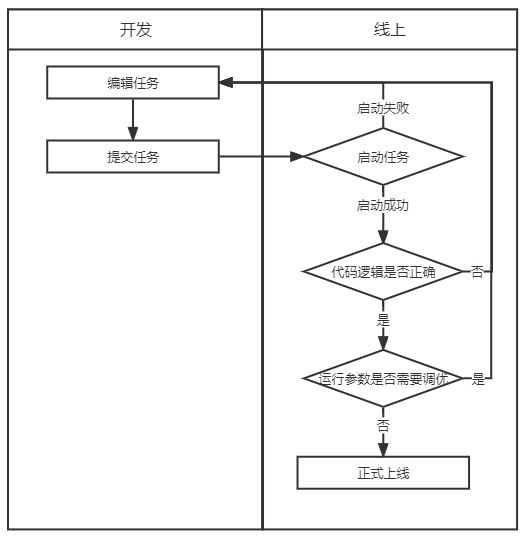
(实时任务开发流程)
由于实时任务在调试过程中需要不断提交到线上运行,调试过程中会产生脏数据,因此一般需要创建一张测试的结果表用于调试,在调试完成后再通过修改代码将结果表替换为正式的结果表。这个替换表的过程涉及到代码变更,可能会引入新的问题,同时维护测试表需要额外的成本。
将任务实际上线运行时,使用的源端数据是任务中指定的源端,大部分实时任务中使用消息队列中的流式数据作为源端,若想在调试阶段使用特定的测试数据进行调试,还需要用户在源端中自行插入指定数据,或使用测试源端表,在调试结束正式上线前替换为正式的源端表。操作复杂,同时也有可能在替换源端或插入数据时引入新的问题。
针对上述痛点 , 有数实时计算平台提供了 相应的解决方案,即 实时开发调试的功能。调试功能分为两个步骤,第一步是获取调试数据,第二步是使用调试数据进行任务本地调试。
在获取调试数据步骤中,目前提供了在线采样、上传本地数据、在线维护测试数据的功能。用户可直接使用在线采样功能,针对任务中使用的源表进行采样,在后续的调试过程中即可直接使用采样的数据。
针对用户想使用特定的测试数据进行任务调试的需求,平台支持用户在在线采样后对采样结果进行编辑和保存,保存采样数据后,这份数据将作为这个任务可长期重复使用的调试数据记录在任务中。此外用户还可以下载源端数据结构文件,自行填写源端数据后上传至任务中,作为此任务的测试样本进行保存。
在获取到调试的样本数据后,用户无需将任务提交上线即可开始调试,同时任务的调试结果将不会写入结果表中,仅会在开发IDE中进行展示,方便用户确认代码逻辑是否正确。
通过任务本地调试的功能,免除了用户需要频繁上线任务的过程,也省去了创建测试结果表和替换结果表代码的过程,为实时任务开发提高了效率,也保障了线上数据的安全。
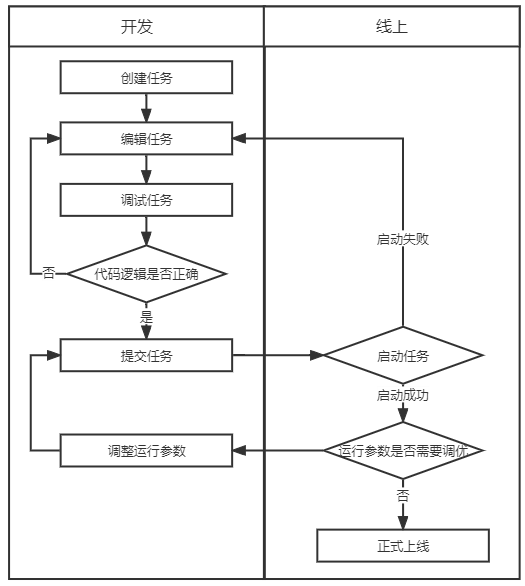
(使用调试功能后实时任务开发流程)
通过调试任务功能,用户在开发环节中即可验证代码逻辑。后续有数实时计算平台将在运行参数调优方面持续做出优化,彻底解决用户调试实时任务难的问题。
业务方需要使用商品售卖结果的实时数据进行报表展示,数据加工团队需要使用 Kafka 消息队列中的商品实时销售情况关联包含商品详情的 MySQL 维表,将结果写入 MySQL 结果表中供业务方查询。
使用的 Kafka topic:testgoods, 数据预览:
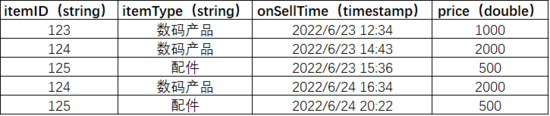
使用的 MySQL 维表:goods_info,包含商品ID和商品名称, 数据预览:
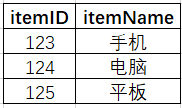
表结构:
(1)创建一个 SQL 任务
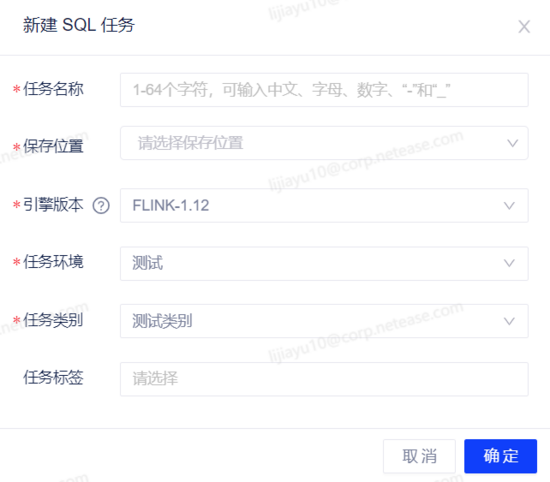
(2)编写业务逻辑
set 'testgoods.connections.group.id' = 'mysql_join_example';
--设置Kafka消费者组id,需要更改为自己命名的groupid
set 'testgoods.scan.startup.mode' = 'earliest-offset';
--设置读取消息队列的位置
create view v1 as
select
PROCTIME() as proctime,
itemID,
itemType,
onSellTime,
price
from
poc.testgoods;
insert into
`ljy_test_mysql`.`sloth_test`.`goods_join_mysql_sink`
select
v1.itemID,
v1.itemType,
v1.onSellTime,
v1.price,
goods_info.itemName as itemName
from
v1
left join `ljy_test_mysql`.`sloth_test`.`goods_info` FOR SYSTEM_TIME AS of v1.proctime on v1.itemID = goods_info.itemID;
(1)进行源表和维表采样
点击页面中的添加 source 按钮,在 source 块中选择源表和维表,点击 source 块中的调试按钮进行采样。
源表 source 块:此处提前将 Kafka的topic:testgoods登记为一张流表,因此有数据库、表的选择。
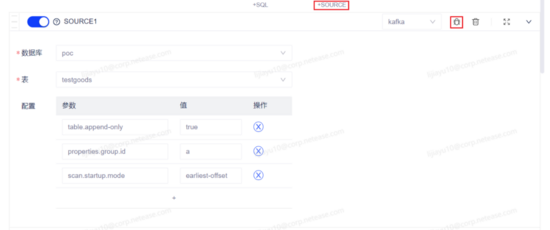
源表采样结果:

维表 source 块:
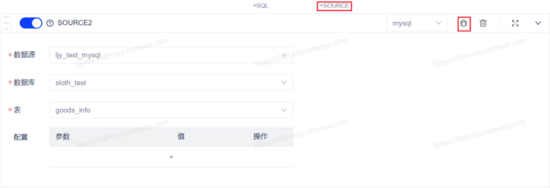
维表采样结果:
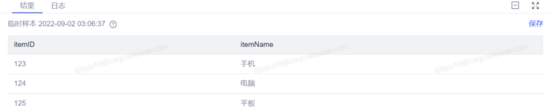
在获取到采样结果后,双击结果栏中的数值可修改样本数据,点击保存按钮可将样本保存为正式样本用于后续多次调试。
(2)调试任务
点击 SQL 块操作栏中的调试按钮,系统将自动解析代码中使用的源表和维表并展示在调试侧边栏中,用户选择每张源表和维表需要使用的样本数据后,即可对任务代码开始调试,调试结果展示在代码框下方。
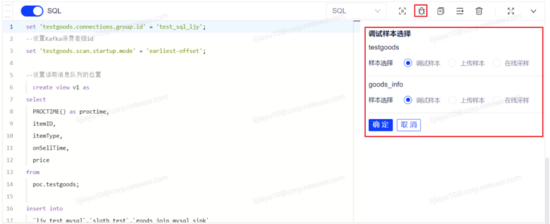
调试结果符合用户预期,代码逻辑验证通过,任务可提交上线。
目前 Apache Flink 已成为大数据实时计算的事实标准,具备高性能、低延迟等特点,但作为一款开源产品,社区版 Apache Flink 在产品化方面并未投入较大精力,因此企业用户在使用社区版 Flink 时,开发门槛高、运维成本高,针对这些问题,我们基于 Apache Flink 构建了一站式、企业级,高性能实时大数据处理系统。
在开发方面,为用户提供了一站式的开发控制台进行任务开发,提供元数据中心进行元数据管理,内置丰富 connector 达到开箱即用的效果,保证了与用户使用的大数据组件无缝对接,提供UDF管理功能、在线调试功能、版本管理功能,大大降低了实时计算任务的开发门槛。
在运维方面,提供全链路监控告警、任务是在检索和基于元数据中心的任务血缘,帮助用户快速发现问题定位问题,提供企业级权限管理保障线上数据安全。
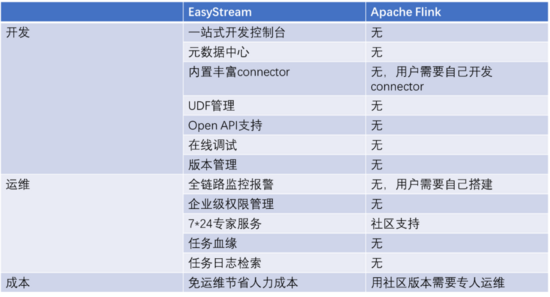
(有数实时计算平台与 Apache Flink 的功能对比)
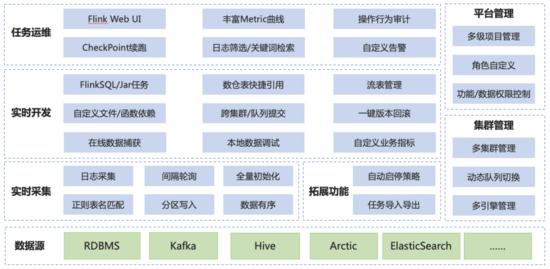
(有数实时计算 平 台 架构)
作者简介
佳钰,网易数帆有数实时计算平台产品经理 。

 暂无任何评论,欢迎留下你的想法
暂无任何评论,欢迎留下你的想法






